
Lesson Progress
0% Complete
Alexa, Siri 등과 같은 개인 비서가 어떻게 작동하는지 궁금한 적이 있습니까? 어떤 규칙이 그들을 지배합니까? 직접 구축하는 방법은 무엇입니까? 귀하의 대답이 ‘예’라면 훌륭합니다!! 자연어 처리에 대해 알아봅시다.

NLP(자연어 처리)란 무엇입니까?
- NLP는 인간의 언어를 자연어(예: 영어, 프랑스어 등)라고 하는 말과 글로 이해하는 컴퓨터 프로그램의 능력입니다.
- NLP는 컴퓨터 과학 및 언어학의 학제 간 분야입니다. NLP의 궁극적인 목표는 컴퓨터를 만들고 우리처럼 인간의 언어를 이해하고 생성하는 것입니다 . 그것도 일반적으로 2-4개 언어를 아는 우리 인간과 달리 모든 인간 언어입니다.
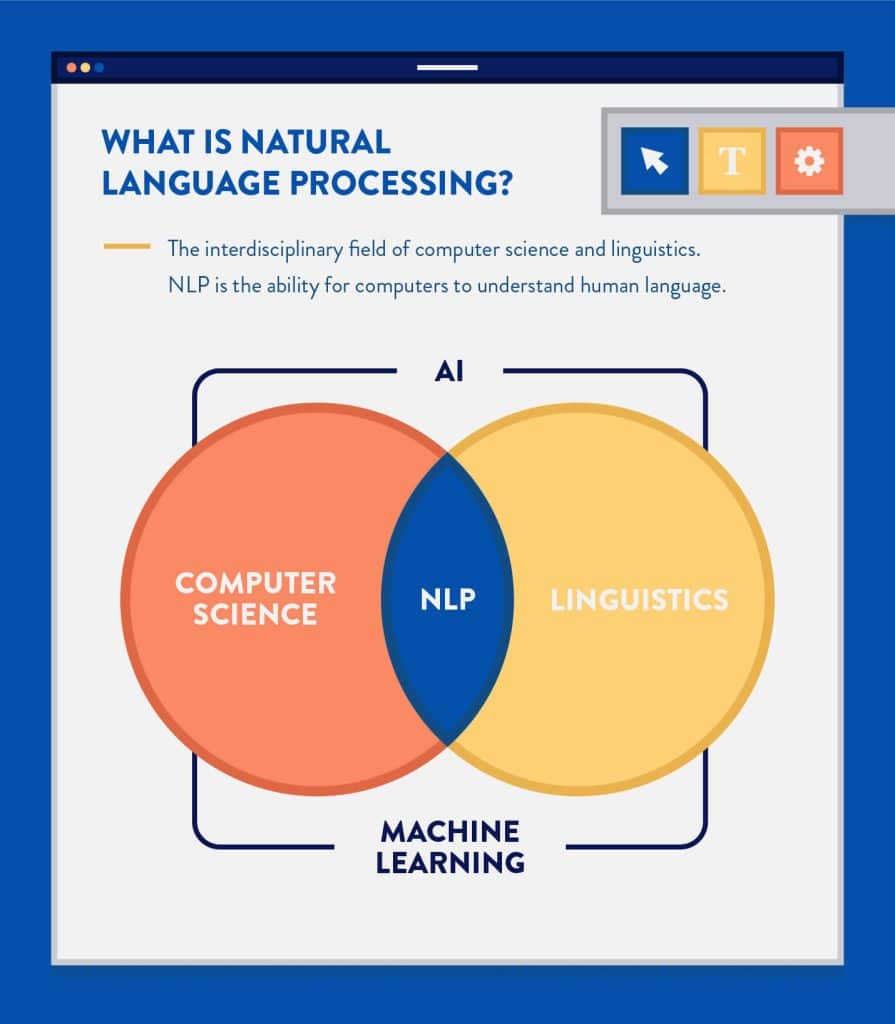
출처: smarttap.com - NLP 분야는 세 부분으로 나뉩니다.
- 음성 인식 – 음성 언어를 텍스트로 번역합니다.
- 자연어 이해 — 우리가 말하는 것을 이해하는 컴퓨터의 능력.
- 자연어 생성 — 컴퓨터에 의한 자연어 생성.
NLP는 어떻게 작동합니까?
자연어 처리에는 두 가지 주요 단계가 있습니다.
- 데이터 전처리
- 알고리즘 개발
NLP의 데이터 전처리
데이터 전처리는 기계 학습 알고리즘에 의해 효율적인 방법으로 분석될 수 있도록 텍스트 데이터를 정리하고 준비하는 것입니다. 전처리는 모델/알고리즘이 해당 텍스트의 기능을 훨씬 더 쉽고 정확하게 감지할 수 있도록 데이터를 변환하여 더 나은 분석과 더 나은 성능으로 이어집니다.
다음은 텍스트 데이터를 NLP 모델/알고리즘에 공급하기 전에 텍스트 데이터를 처리하기 위해 따라야 하는 기본 단계입니다.
- 토큰화: 작업을 위해 텍스트를 더 작은 단위로 나누는 것 예: 단순히 단어로 나누는 것.
- 중지 단어 제거: 텍스트에서 문맥에 많은 의미를 추가하지 않는 일반 단어 제거(예: is, and, of, a, an 등)
- Lemmatization: 동일한 종류의 단어 또는 동일한 단어의 변형 형태를 함께 그룹화합니다. 예: 단어: run, running, ran, dart, scurry 등은 같은 종류의 의미를 전달합니다.
- 품사 태깅: 명사, 동사, 부사, 형용사 등 단어가 속한 품사를 기준으로 단어에 태깅을 합니다.
데이터가 처리되면 이를 추가로 모델링하기 위한 알고리즘이 개발됩니다.
NLP의 알고리즘 개발
NLP의 과학적 발전은 다음 부분으로 나눌 수 있습니다.
- 규칙 기반 시스템-
- 이름에서 알 수 있듯이 이 시스템은 언어와 관련된 많은 도메인별 규칙을 만드는 데 의존합니다.
- 이 방법은 구조화되지 않은 데이터(예: 웹 페이지, 이메일)에서 구조화된 데이터(예: 날짜, 이름)를 추출하는 것과 같은 간단한 작업을 자동화할 수 있습니다.
- 그러나 인간 언어의 복잡성으로 인해 규칙 기반 시스템은 문장의 맥락을 파악하는 데 약하고 정확도가 낮으며 여러 도메인에 걸쳐 일반화할 수 없습니다.
- 고전적인 기계 학습-
- 이 방법에서 우리는 기계 학습 모델이 규칙을 정의하는 대신 스스로 언어의 규칙을 학습하도록 합니다.
- 모델은 특정 언어의 기능을 학습하며, 기능 엔지니어링(예: 단어 모음, 품사 등)을 사용하여 최적화할 수 있습니다. Naive Bayes와 같은 기계 학습 모델은 이 기술을 사용하여 훈련됩니다.
- 이 모델은 교육 데이터를 사용하여 언어의 패턴을 찾은 다음 보이지 않는 데이터에 대해 예측합니다.
- 딥 러닝 모델-
- NLP용 딥 러닝 모델을 사용하는 것은 현재 NLP 분석 및 연구를 수행하는 가장 인기 있는 방법입니다.
- 이러한 모델은 NLP 분석 및 예측에서 모든 기계 학습 모델의 가장 높은 정확도를 허용합니다.
- 기존 기계 학습 모델과 달리 딥 러닝 모델에는 수작업으로 만든 기능이나 기능 엔지니어링이 필요하지 않습니다. 학습 데이터에서 특징 추출 및 엔지니어링을 자동으로 수행할 수 있기 때문입니다.