이전 학습에서는 PictoBlox 내에서 기계 학습 환경을 사용하는 방법에 대해 소개했습니다. 마스크 감지를 위한 프로젝트를 생성하고 다음 3개 클래스에 대한 데이터를 업로드했습니다.
- Mask On
- Mask Off
- Mask Wrong
이 세션에서는 이전 강의에 이어 이전 강의에서 업로드한 데이터/이미지를 사용하여 마스크 감지 기계 학습 모델의 교육을 수행합니다. 그런 다음 실시간 데이터에서 모델의 성능을 테스트합니다.
모델 훈련
이제 데이터를 수집했으므로 새로운 보이지 않는 데이터를 이 세 가지 클래스로 분류하는 방법을 모델에 가르칠 차례입니다. 이를 위해 우리는 기차 모델. 모델을 교육함으로써 이미지에서 의미 있는 정보를 추출하고 이를 업데이트합니다. 무게. 이러한 가중치가 저장되면 모델을 사용하여 이전에 본 적이 없는 데이터를 예측할 수 있습니다.
그러나 모델을 교육하기 전에 알아야 할 몇 가지 하이퍼 매개변수가 있습니다. ” Advanced ” 탭을 클릭하면 볼 수 있습니다.
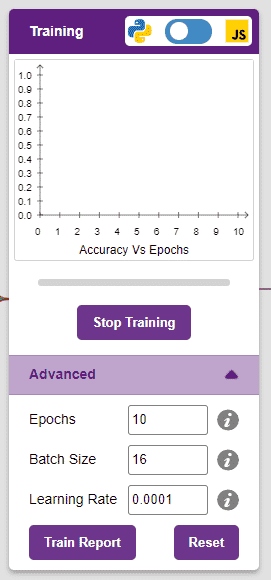

여기에서 함께 사용할 수 있는 세 가지 하이퍼파라미터가 있습니다.
- Epochs– 교육 모델을 통해 데이터가 공급되는 총 횟수입니다. 따라서 10 epoch에서 데이터 세트는 교육 모델을 통해 공급됩니다. 10회 . epochs 수를 늘리면 종종 성능이 향상될 수 있습니다.
- 배치 크기– 한 단계에서 사용될 샘플 세트의 크기. 예를 들어, 데이터 세트에 160개의 데이터 샘플이 있고 배치 크기가 16인 경우 각 에포크는 160/16=10단계 . 이 하이퍼 매개변수를 변경할 필요가 거의 없습니다.
- 학습률 – 단계를 반복한 후 모델이 가중치를 업데이트하는 속도를 나타냅니다. 이 매개변수를 조금만 변경해도 모델 성능에 큰 영향을 미칠 수 있습니다 . 일반적인 범위는 0.001에서 0.0001 사이입니다.
표준 하이퍼파라미터로 모델을 훈련하고 성능을 살펴보겠습니다. Python Coding Environment에서 작업하고 있으므로 Python(JS 아님)에서만 모델을 교육할 수 있습니다.
학습을 시작하려면 ” Train Model ” 버튼을 클릭합니다. 이 모델의 하이퍼파라미터는 변경할 필요가 없습니다.
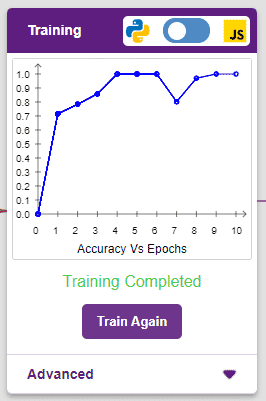
모델은 훌륭한 결과를 보여줍니다! 정확도 그래프의 판독값이 높을수록 모델이 더 좋다는 것을 기억하십시오. 그래프의 x축은 epochs를 나타내고 y축은 해당 정확도를 나타냅니다. 정확도 범위는 0~1입니다.
모델 테스트
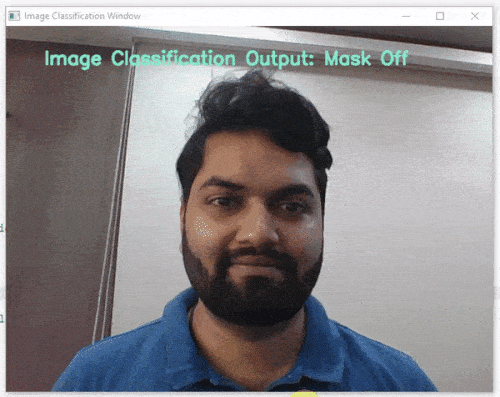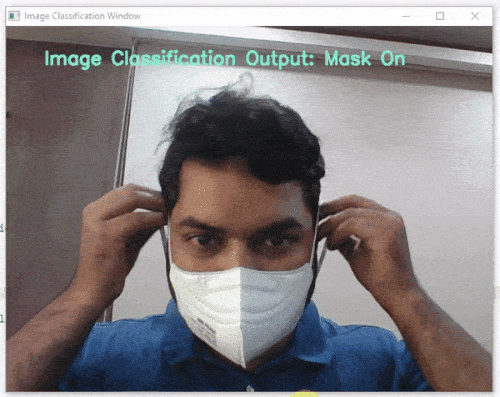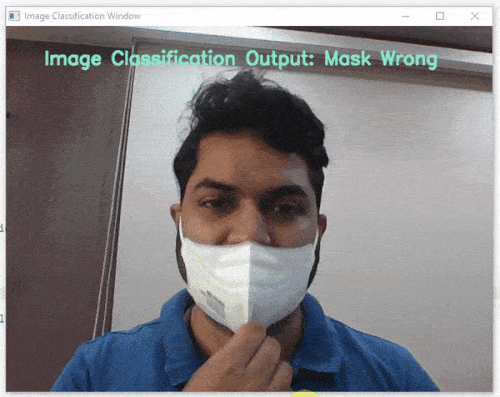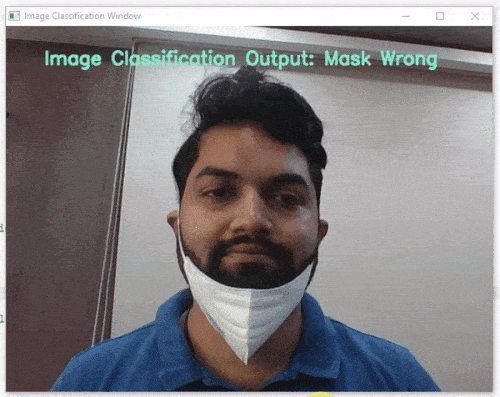
이제 모델이 훈련되었으므로 예상한 결과를 제공하는지 살펴보겠습니다. 장치의 카메라를 사용하거나 장치 저장소에서 이미지를 업로드하여 모델을 테스트할 수 있습니다. 웹캠을 사용하여 시작하겠습니다.
테스트 상자에서 “Webcam” 옵션을 클릭하면 모델이 창의 이미지를 기반으로 예측을 시작합니다.
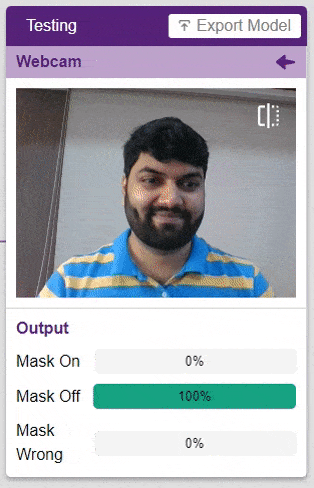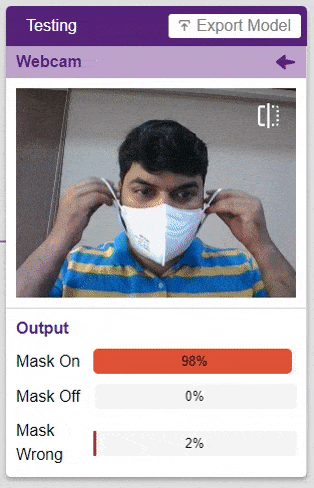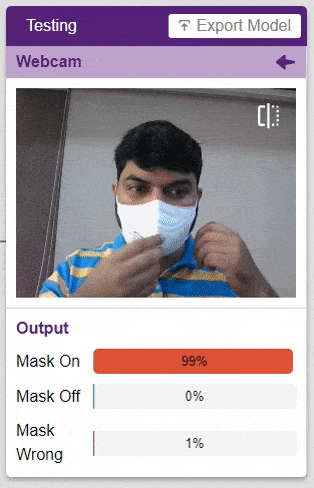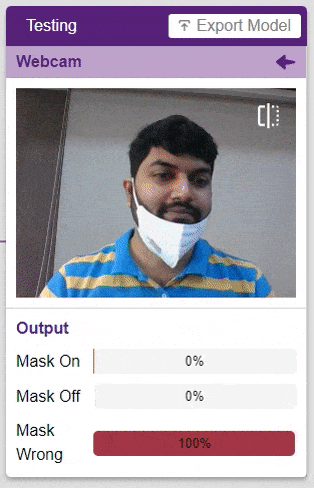
엄청난! 이 모델은 실시간으로 예측할 수 있습니다. 이제 테스트 상자의 오른쪽 상단에 있는 십자가를 클릭하여 창을 닫습니다.
이제 모델을 내보내고 Python coding 환경에서 프로젝트를 만들 수 있습니다.
모델을 Python 환경으로 내보내기
테스트 상자의 오른쪽 상단에 있는 ” Export Model ” 버튼을 클릭하면 PictoBlox가 모델을 Python 환경으로 로드합니다.
테스트할 준비가 된 Python 테스트 코드가 스크립팅 영역에 자동으로 표시되는지 확인합니다.
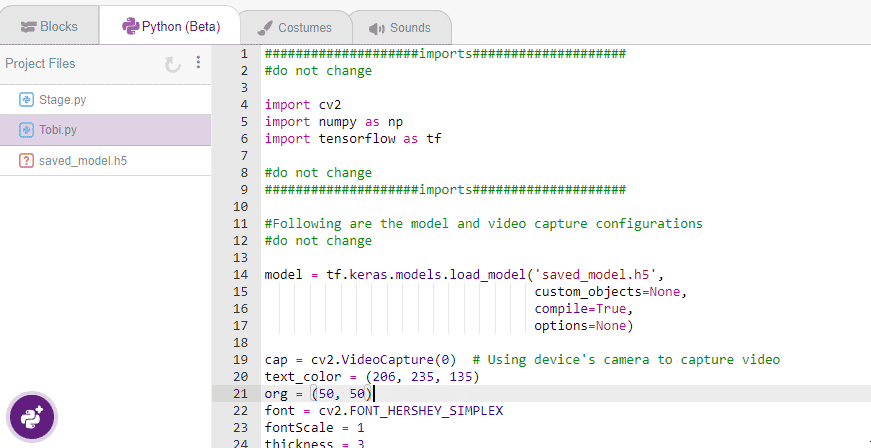
Beautify 버튼을 클릭하여 들여쓰기 오류가 없는 코드를 만듭니다. A+ 아이콘(Magic Wand)에서 왼쪽에 있는 아이콘입니다.

다음은 PictoBlox에서 생성한 코드입니다.
####################imports####################
#do not change
import cv2
import numpy as np
import tensorflow as tf
#do not change
####################imports####################
# Following are the model and video capture configurations
# do not change
model = tf.keras.models.load_model('saved_model.h5',
custom_objects=None,
compile=True,
options=None)
cap = cv2.VideoCapture(0) # Using device's camera to capture video
text_color = (206, 235, 135)
org = (50, 50)
font = cv2.FONT_HERSHEY_SIMPLEX
fontScale = 1
thickness = 3
class_list = ['Mask Off', 'Mask On', 'Mask Wrong'] # List of all the classes
#do not change
###############################################
#This is the while loop block, computations happen here
while True:
ret, image_np = cap.read() # Reading the captured images
image_np = cv2.flip(image_np, 1)
image_resized = cv2.resize(image_np, (224, 224))
img_array = tf.expand_dims(image_resized,
0) # Expanding the image array dimensions
predict = model.predict(img_array) # Making an initial model prediction
predict_index = np.argmax(predict[0],
axis=0) # Generating index out of the prediction
predicted_class = class_list[
predict_index] # Tallying the index with class list
image_np = cv2.putText(
image_np, "Image Classification Output: " + str(predicted_class), org,
font, fontScale, text_color, thickness, cv2.LINE_AA)
print(predict)
cv2.imshow("Image Classification Window",
image_np) # Displaying the classification window
###############################################
#Add your code here
#Add your code here
###############################################
if cv2.waitKey(25) & 0xFF == ord(
'q'): # Press 'q' to close the classification window
break
cap.release() # Stops taking video input
cv2.destroyAllWindows() #Closes input window이 코드는 세 가지 라이브러리를 사용합니다.
- OpenCV – 이미지 캡처 및 이미지 처리용
- Numpy – 배열 조작용
- Tensorflow – 기계 학습용
Run 버튼을 클릭하여 코드를 실행하고 테스트합니다.