
Lesson Progress
0% Complete
왜 머신러닝을 배워야 할까요?
기계 학습(ML)은 현재 기술 분야에서 가장 많이 언급되는 주제 중 하나이며 앞으로도 그럴 것입니다. 그 이유는 다음과 같습니다.
- 오늘날 텍스트, 이미지, 비디오, 지리적 위치 등의 형태로 생성되는 많은 양의 데이터 .
- 계산 능력이 향상 되어 데이터 분석 속도가 빨라지고 비용이 절감됩니다.
- 더 나은 알고리즘의 개발 로 더 나은 분석, 더 나은 예측력 및 더 높은 정확도로 이어집니다.
오늘날 기계 학습은 일상적인 애플리케이션부터 고급 애플리케이션에 이르기까지 모든 곳에서 사용되고 있습니다.
기계 학습의 일상적인 응용 프로그램의 몇 가지 예는 다음과 같습니다.
- Google 검색 및 페이지 순위
- YouTube 동영상, 아마존 쇼핑 등을 위한 추천 엔진
- 이미지 태깅에서 얼굴 인식
- 언어 번역(Google 번역 사용)
기계 학습의 고급 응용 프로그램에 대한 몇 가지 예는 다음과 같습니다.
- 엑스레이 이미지에서 암 감지
- 자동 내비게이션을 위한 자율주행차
- 고도 조정을 위한 항공기 제어
- 결함 샘플 감지와 같은 제조 분야의 컴퓨터 비전
- 위협 탐지를 위한 보안 시스템의 컴퓨터 비전
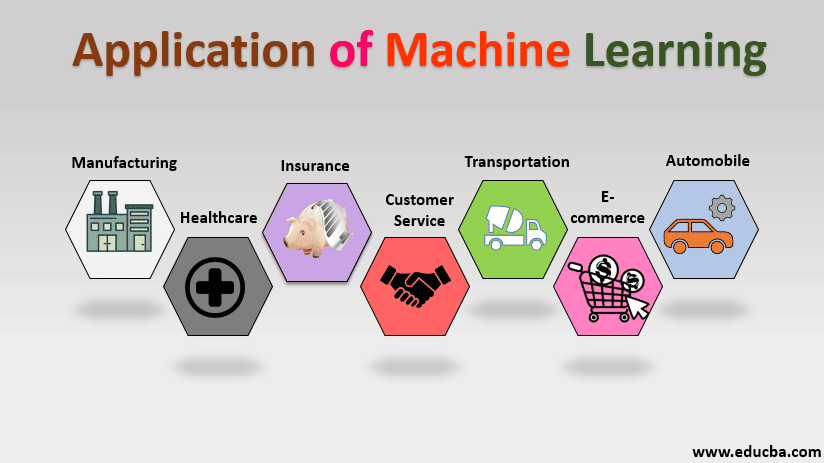
머신 러닝은 지속적으로 발전하는 분야로, 앞으로 몇 년 동안 점점 더 많은 응용 분야를 계속 다룰 것이며 이러한 모든 영역에서 성능을 지속적으로 개선하여 기술 발전과 비즈니스 성장을 주도할 것입니다.
기계 학습이란 무엇입니까?
- 기계 학습은 인공 지능의 하위 분야입니다. 기계 학습 자체는 인간의 두뇌에서 영감을 얻은 기계 학습 알고리즘 클래스인 딥 러닝과 같은 다른 하위 필드를 가질 수 있습니다.
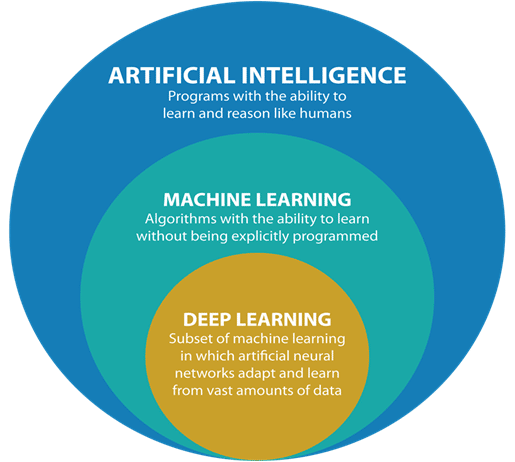
- AI와 기계 학습은 컴퓨터 과학의 한 분야이지만 기존의 컴퓨팅 접근 방식과 다릅니다.
- 전통적인 컴퓨팅 에서 알고리즘은 우리가 명시적으로 프로그래밍 하고 문제를 해결하기 위해 컴퓨터에서 사용하는 단계별 지침입니다.
- 반면에 기계 학습 알고리즘은 통계 분석/모델링 접근 방식을 사용하여 제공된 데이터에서 학습 하고 자체 규칙 집합을 만듭니다. 그런 다음 ML 알고리즘은 데이터에서 학습한 이러한 규칙 집합을 기반으로 결정을 내릴 수 있습니다.
기계 학습의 유형
기계 학습 알고리즘은 크게 3가지 범주로 분류할 수 있습니다.
- 지도 학습
- 비지도 학습
- 강화 학습
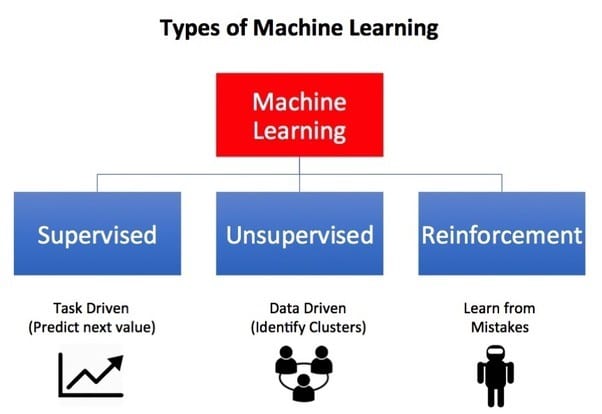
ML 알고리즘은 학습에 사용되는 데이터의 유형과 데이터에서 학습된 각 항목의 피드백이 모델에 다시 제공되는 방식에 따라 이 세 그룹으로 분류됩니다.
- 지도 학습
- 감독 학습에서 ML 모델은 레이블이 지정된 교육 데이터와 함께 제공됩니다. 즉, 각 데이터에 올바른 레이블이 지정되어 있습니다.
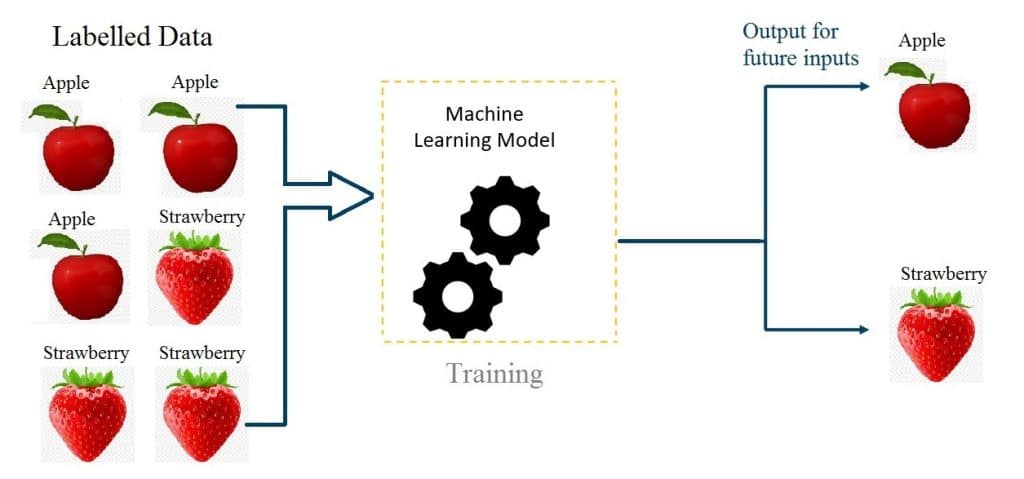
출처: ai.plainenglish.io ML 모델은 레이블이 지정된 이 데이터를 살펴보고 이 교육 데이터에서 패턴/규칙을 학습합니다 . 입력 데이터/변수에서 출력 데이터로 함수 매핑을 생성하여 학습합니다 . 이를 통해 모델은 ‘테스트 데이터’라고도 하는 보이지 않는 새로운 데이터를 충분히 예측할 수 있습니다.
- 지도 학습은 다음과 같이 더 나눌 수 있습니다.
- 분류: 출력 변수(예측할 변수)가 범주일 때 사용합니다.
예를 들어 특정 이메일이 스팸인지 스팸이 아닌지 주어진 입력 데이터에서 예측합니다. 특정 환경 조건(입력 변수)으로부터 날씨가 맑거나 흐리거나 비가 올 것인지를 예측합니다. 등. - 회귀: 출력 변수가 수치일 때 사용 예: 수업 중 학생의 가중치
- 분류: 출력 변수(예측할 변수)가 범주일 때 사용합니다.
- 감독 학습에서 ML 모델은 레이블이 지정된 교육 데이터와 함께 제공됩니다. 즉, 각 데이터에 올바른 레이블이 지정되어 있습니다.
- 비지도 학습
- 비지도 학습에서 ML 모델에는 올바른 출력 값으로 레이블이 지정되지 않은 훈련 데이터 세트가 제공됩니다(지도 학습과 달리). 여기서 모델은 실제 레이블(출력 변수)에서 학습하는 것이 아니라 입력 데이터 자체의 고유한 패턴을 통해 데이터에서 패턴을 찾습니다.
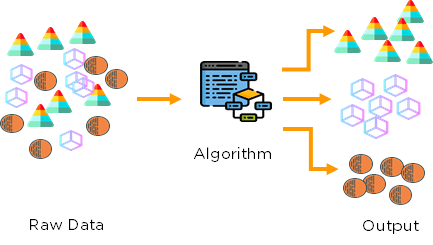
출처: Medium.com - 비지도 학습은 다음과 같이 더 나눌 수 있습니다.
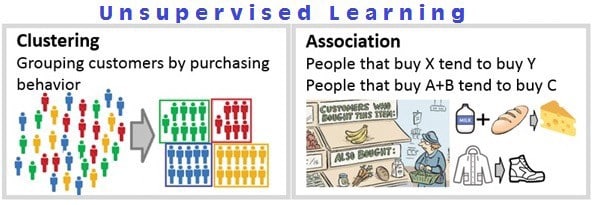
- 클러스터링: amazon.com과 같은 전자 상거래 웹 사이트에서 고객을 구매 행동별로 그룹화하는 것과 같이 데이터 및 양식 그룹 내에서 고유한 패턴을 발견합니다.
- 연결: 이러한 종류의 알고리즘은 데이터에서 연결 규칙을 학습합니다. 이러한 연관 규칙은 데이터의 많은 부분을 설명합니다.
- 비지도 학습에서 ML 모델에는 올바른 출력 값으로 레이블이 지정되지 않은 훈련 데이터 세트가 제공됩니다(지도 학습과 달리). 여기서 모델은 실제 레이블(출력 변수)에서 학습하는 것이 아니라 입력 데이터 자체의 고유한 패턴을 통해 데이터에서 패턴을 찾습니다.
- 강화 학습
- ‘에이전트’라고도 하는 강화 학습 알고리즘은 환경과 상호 작용하여 학습합니다. 에이전트가 활동을 정확/정확하게 수행하면 보상을 받고 에이전트가 활동을 잘못 수행하면 페널티를 받습니다.
- ‘보상’을 최대화하고 ‘벌금’을 최소화 함으로써 에이전트는 인간의 개입 없이 특정 작업을 학습합니다 .
- 따라서 강화 학습은 보상 및 처벌/처벌 시스템을 사용하여 기계 학습 모델을 훈련시키는 일종의 동적 프로그래밍입니다.
- 강화 학습의 예:
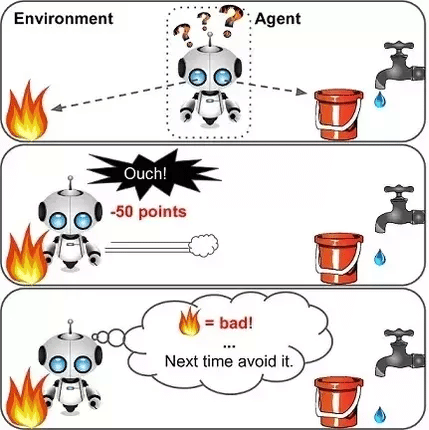
이미지에 표시된 것처럼 에이전트에는 물이 있는 경로 또는 불이 있는 경로의 두 가지 옵션이 제공됩니다. 에이전트가 불길을 사용하면 불길에서 50점을 빼서 벌점을 얻습니다. 이렇게 하면 에이전트는 불길을 피해야 한다는 것을 학습합니다. 안전한 길인 물길을 선택하면 50점이 됩니다. 대리인에게 보상합니다. 이런 식으로 에이전트는 물길이 안전한 길이라는 것을 알게 됩니다. 이런 식으로 보상-페널티 시스템을 사용하여 에이전트는 어떤 길이 안전하고 어떤 길이 안전하지 않은지 배우게 됩니다. 따라서 다음 조치를 선택하기 위해 환경 지식을 향상시킵니다.